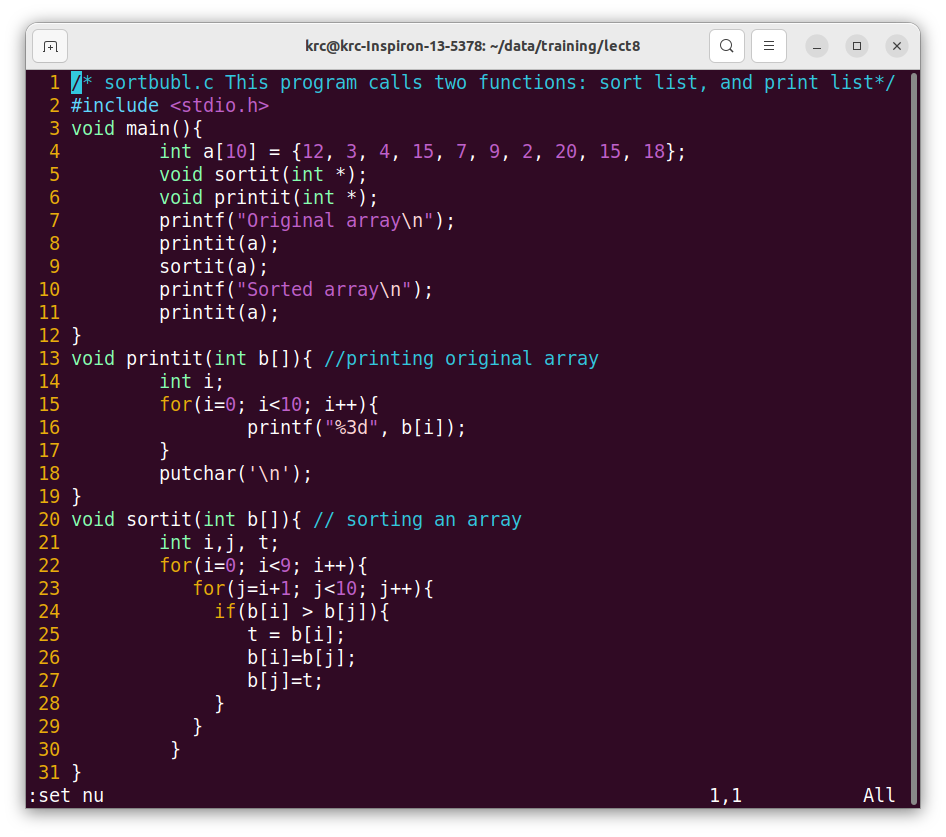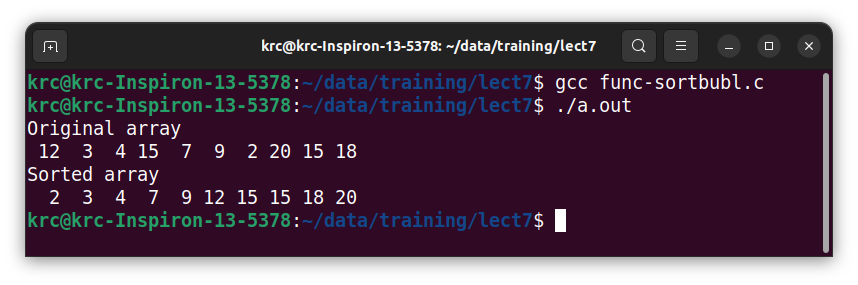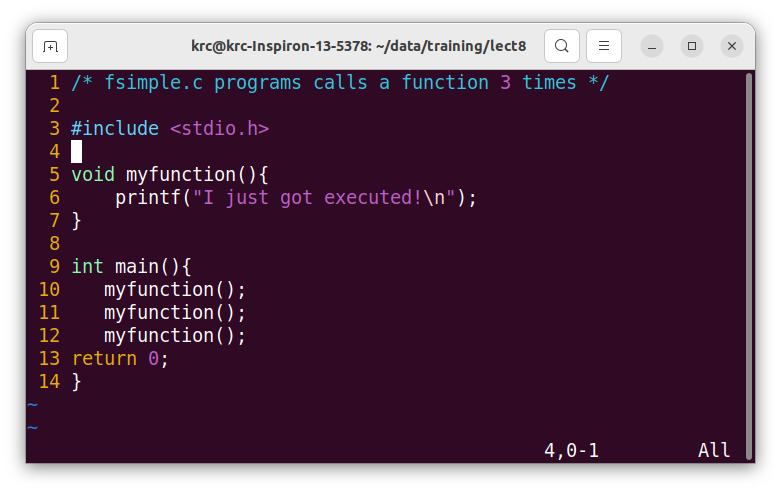
Figure 8.1: Function calls to print, sort
Computer Fundamentals with C and Unix
(Sorting and Functions)
Lecture 08: Jan. 09, 2023 Prof. K.R. Chowdhary : Professor of CS
Disclaimer: These notes have not been subjected to the usual scrutiny reserved for formal publications. They may be distributed outside this class only with the permission of the Instructor.
The count of the element is small the number of iterations in the sorting will be less. As the number grows the number of iterations also increases. Now suppose we have a record of elements inside a database having count of several thousands. The problem comes with the performance of the sorting. Computer takes much longer time to sort the elements in the list. Efficiency of a sorting algorithm is often expressed with the order of O(n) and denoted with Big-O notation. A simple sorting algorithm implements two loops where outer loop can grow to N and for each iteration of outer loop, the inner loop can take (N - 1) iterations. So total number of steps for this sorting algorithm will be N times (N - 1). This sorting will have a time complexities of the order of O(n * n) or O(n2). A sorting algorithms is always chosen based on its time performance. Order of O(n2) is for small number of elements but not a good value for considering a large number of elements. Some sorting algorithms uses recursion and better logic to give better performance. We will discuss all algorithms one by one.
Merge sort can be used for external sorting also. In that case, a subset of the entire list of the elements are loaded in main memory and sorted at a time.
These sorting algorithms are one of the most used in computer science. Each algorithm has its own advantage and disadvantage and complexity. Reader must have a good understanding of complexity and big O notation before he/she can understand the efficiency of each algorithm. We will discuss each algorithm in details in the next few sections. We will explain the mechanism and will give an example with code in C language to understand the algorithm deeply.
Another problem comes when the size of individual elements are large and total number of elements are also large that the entire list of elements cannot be fitted in main memory for sorting at one go. Entire elements are then divided into smaller groups. Groups are sorted and merged back.
Therefore considering the scale, the sorting mechanism has been divided into are two main categories :-
Internal sorting
External sorting
Internal sorting is done by loading all the elements in the main memory.
When individual element size is more and number of elements are large enough to hold all the elements in main memory, then external sorting is used. External sorting loads a portion of elements from secondary memory (like HDD) in main memory and sorts and then saves back to secondary storage. Later all the individual sorted fragments are merged in the main group.
We are discussing mainly internal sorting here. There are several algorithms used for this purpose each one has its own optimization techniques to execute the sort task in minimum CPU cycle thus to save time and energy.
There are the several internal sorting used in practical fields.
Bubble Sort- A sorting algorithm which compares one element to its next element and if requires it swaps like a bubble.
Selection Sort - A sorting algorithm which selects a position in the elements and compares it to the rest of the positions one by one.
Insertion Sort - A sorting algorithm which selects one element from the array and is compared to the one side of the array. Element is inserted to the proper position while shifting others.
Quick Sort - A sorting algorithm which divides the elements into two subsets and again sorts recursively.
Heap Sort - A sorting algorithm which is a comparison based sorting technique based on Binary Heap data structure. ,
Merge sort - A sorting algorithm which divides the elements to subgroups and then merges back to make a sorted.
Radix Sort - A sorting algorithm used for numbers. It sorts the elements by rank of the individual digit What we have discussed is bubble sort. Other are mostly more efficient, but complex.
In c, we can divide a large program into the basic building blocks known as function.
The function contains the set of programming statements enclosed by {}. A function
can be called multiple times to provide reusability and modularity to the C program.
In other words, we can say that the collection of functions creates a program. The
function is also known as procedure or subroutine in other programming languages. In
summary:
A function is a block of code which only runs when it is called.
You can pass data, known as parameters, into a function.
Functions are used to perform certain actions, and they are important for reusing code: Define the code once, and use it many times.
So it turns out you already know what a function is. You have been using it the whole time while studying this tutorial!
For example, main() is a function, which is used to execute code, and printf() is a function; used to output/print text to the screen:
int main() {
printf("Hello World!");
return 0;
}
To create (often referred to as declare) your own function, specify the name of the function, followed by parentheses () and curly brackets {}:
void myFunction() {
// code to be executed
}
The Declared functions are not executed immediately. They are ”saved for later use”, and will be executed when they are called. To call a function, we write the function’s name followed by two parentheses ”()” and a semicolon ”;”
In the following example, myFunction() is used to print a text (the action), when it is called:
int main() {
myFunction(); // call the function
return 0;
}
// Create a function
void myFunction() {
printf("I just got executed!");
}
The function will output:
"I just got executed!"
In the following we call the same function three times:
void myFunction() {
printf("I just got executed!");
}
int main() {
myFunction();
myFunction();
myFunction();
return 0;
}
The result will be :
I just got executed!
I just got executed!
I just got executed!
There are the following advantages of C functions.
By using functions, we can avoid rewriting same logic/code again and again in a program.
We can call C functions any number of times in a program and from any place in a program.
We can track a large C program easily when it is divided into multiple functions.
Reusability is the main achievement of C functions.
However, Function calling is always a overhead in a C program
There are three aspects of a C function.
Function declaration: A function must be declared globally in a c program to tell the compiler about the function name, function parameters, and return type.
Function call: Function can be called from anywhere in the program. The parameter list must not differ in function calling and function declaration. We must pass the same number of functions as it is declared in the function declaration.
Function definition: It contains the actual statements which are to be executed. It is the most important aspect to which the control comes when the function is called. Here, we must notice that only one value can be returned from the function.
There are two types of functions in C programming:
Library Functions: are the functions which are declared in the C header files such as scanf(), printf(), gets(), puts(), ceil(), floor() etc.
User-defined functions: are the functions which are created by the C programmer, so that he/she can use it many times. It reduces the complexity of a big program and optimizes the code.
The Fig. 8.1 has a simple functions defined, and the main calls this three times.